前几天,在 使用docker-compose搭建nextcloud+Nginx+MySQL+Redis 这篇文章中的 这条评论 引起了我的好奇心。这位兄弟的评论内容大致是想要将 Nextcloud 与 Aria2 联动实现网盘上的离线下载功能。
在看到这个主意后,转念一想,就目前市面上来看,离线下载不是已经成为一个网盘应用的基础功能了吗?我这 Nextcloud 那也必须整上啊 🤣 !二话不说就开整。
经过几次尝试后,大致找到了一个能够与 使用docker-compose搭建nextcloud+Nginx+MySQL+Redis 这篇文章中的 nextcloud 整体方案能够完美兼容,并实现部署后简单配置即可使用的效果。
大致思路
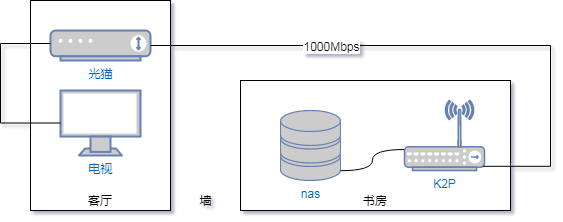
套方案是基于 使用docker-compose搭建nextcloud+Nginx+MySQL+Redis 这篇文章中搭建好的 Nextcloud 整体解决方案实现的,所以在部署上是沿用了 docker-compose 这种简单快速且方便迁移的基本方法。
而就 Nextcloud 与 Aria2 的交互方法采用的是目前已经成熟了且完美兼容 Nextcloud 的插件 ocDownload。这款插件支持 aria2、youtube-dl、curl 等网络下载组件,但我们这里仅使用 aira2 这一个功能,其他的下载组件看以后是否有充分的需求再去折腾吧 😂 。ocDownloader 与 Aria2 交互的方式是传统的 Aria2-RPC 协议,与 AriaNG 类似,也是一个可独立运行的前端,有效与否取决于 Aria2 的服务端是否正常工作。
在使用的过程中,发现 ocDownloader 在连接 Aria2 这方面几乎没有可配置的地方,只能选择在 HTTP 和磁力下载时使用 Aria2 还是 cURL,其余的类似 Aria2 的地址、端口等都找不到配置的地方。所以初步怀疑是 ocDownloader 将 Aria2 的地址和端口写死了,目标连接很可能就是经典的 127.0.0.1:6800。
经过以上的分析,这套操作的主要思路分为以下几步:
具体步骤
配置 Aria2 容器
由于之前的 nextcloud 的 docker 是使用了 docker-compose 来组织容器,所以这次也使用 docker-compose 的形式呈现。
由于 docker-compose 强依赖于 docker-compose.yml 文件中的参数配置,如果 yml 文件中的参数配置在 compose 运行过程中发生了变化,会导致 down 和 up 都发生错误。所以在开始之前,我们先将容器都 down 掉(就是删除容器的意思)。
注意,这里要确保所有重要的数据都映射到了本地磁盘空间中,否则在重启这份 compose 后造成数据丢失。当然,按照我之前文章的映射方法映射后,就不会有问题,重要数据都是映射到本地了。
这里我们可以使用常规的 down 来关闭 compose,并在配置完成后常规 up
1
2
3
4# 关闭 compose
docker-compose down
# 重新构建 compose
docker-compose up -d也可以在全部配置完成后,强行使用新的配置重新构建 compose
1
docker-compose up --force-recreate -d
这里我将 Aria2 的容器命名为 downloader,以下是容器的启动参数。镜像使用的是他人专门给 nextcloud 配置过的 wahyd4/aria2-ui:nextcloud 版本,当然也可以使用其他版本的,例如使用次数最多的 p3terx/aria2-pro,只要是能够配置 uid 和 gid 的就足够了。
1 | downloader: |
- 这里使用 expose 将 6800 端口暴露在 docker 的网络中而不是宿主机的网络中,是因为我们后面要将 downloader 容器连接到 nextcloud 的容器中,只需要这两个容器可以数据交互即可,无需将多余的端口暴露给外部而增加安全风险。
- 这里使用 volumes 将 nextcloud 的
/var/www/html/data以相同路径映射到 aria2 容器中,是因为 ocDownloader 会自动将每个用户创建的下载任务的下载目的路径拼接到 nextcloud 本地的路径中,以实现单个用户下载的数据只能由当前用户使用。 - 配置 PUID 和 PGID 为 33,是因为 nextcloud 容器中运行 nextcloud 进程的用户是
www-data,而这个用户的用户 ID 和组 ID 是33:33,配置了相同的用户 ID 和组 ID 后,就可以让 Aria2 容器中的下载器下载下来的文件的所属权限与 nextcloud 完全相同,并使得两边的进程对这些文件都能操作。 - 不在 environment 中给 Aria2 配置用户名和密码主要也是因为这个容器并不对外暴露,唯一能够接触到这个容器的方式只有通过 nextcloud 容器间接接触,加之不配置认证选项可以降低配置的难度。
配置好 Aria2 的容器后,还需要修改一下 nextcloud 容器的配置,使得两个容器从网络上和数据上做到互通:
1 | app: |
安装 ocDownloader 插件
直接从应用商店安装与自己 nextcloud 匹配的 ocDownloader,或者从 ocDownloader - Apps - App Store - Nextcloud 下载与自己 nextcloud 版本匹配的拓展包上传到服务器后解压安装到 /var/www/html/apps 中。
并启用 ocDownloader。在设置中的“其他设置”中能够看到 ocDownloader 的配置选项,即为安装并启用完成。

此时已经可以可以看到导航栏中的 ocDownloader 图标了,并且可以进入它的页面。但是此时大家会发现,它其实是无法使用的,因为它根本连不上 Aria2 的 RPC。

修改 ocDownloader 插件代码
之前在大致思路中也讲到过,ocDownloader 在插件代码中将连接 Aria2 的地址写死了,导致除了 127.0.0.1:6800,其他地址一律不认。好在整个 nextcloud 体系是建立在 php 语言的基础上的,所有代码都是可以修改后直接运行的,不需要重新编译。
虽然我是做 c++/python 后端开发的,不会 php,但是万变不离其宗,编码的中心思想基本都是通用的。依托于我那蹩脚阅读代码的能力,最后也还是找到了配置 Aria2 连接地址的位置,这里就不卖关子了,直接把文件路径放这里。
容器内的代码路径为
/var/www/html/apps/ocdownloader/controller/lib/aria2.php,如果使用跟我的 docker-compose.yml 一样的映射方式,那么此时在宿主机中的位置就是./app/html/apps/ocdownloader/controller/lib/aria2.php
先进入这个目录:
1 | cd html/apps/ocdownloader/controller/lib/ |
备份一下原文件
1 | cp aria2.php aria2.php.bak |
然后使用编辑器编辑这个文件的第 34 行,或者搜索 self::$Server ,将其赋值的数据从 "127.0.0.1" 改为 "downloader"。
1 | class Aria2 |
我这里改为 "downloader" 是因为我在 docker-compose.yml 中将 Aria2 的容器以 downloader 的名称映射到了 nextcloud 的容器 host 列表中,这样就可以直接通过 downloader 这个地址解析到 Aria2 容器在 docker 网桥内的内网地址。
保存这个文件。
重启重新构建 docker-compose 。
1 | docker-compose up -d |
等待容器完全启动,页面服务可以访问后,就可以在 nextcloud 中使用 ocDownloader 与 Aria2 容器进行交互了!
附录
日志排障
因为这个方法有点骚,每个人在环境中面对的情况可能不一样,所以这里提供一些基本的排障手段。
持续监控查看某个容器的服务日志:
1 | docker logs [容器名/容器ID] -f |
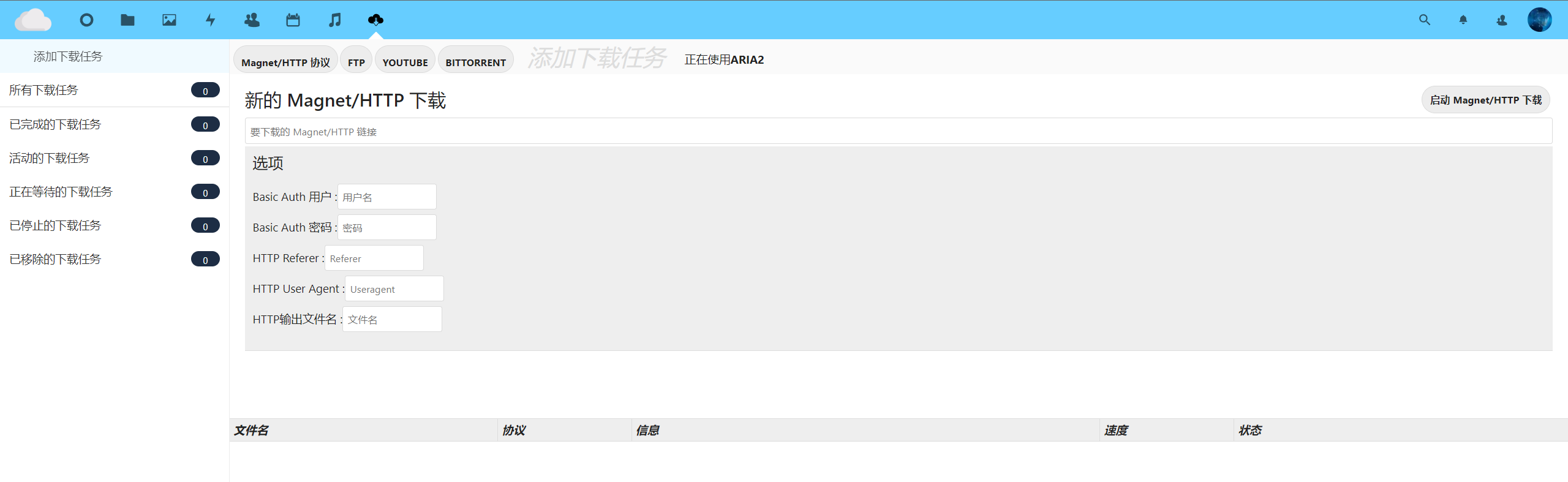
这里我们尝试从页面上的 ocDownloader 下载一个微信的 windows 端安装包。
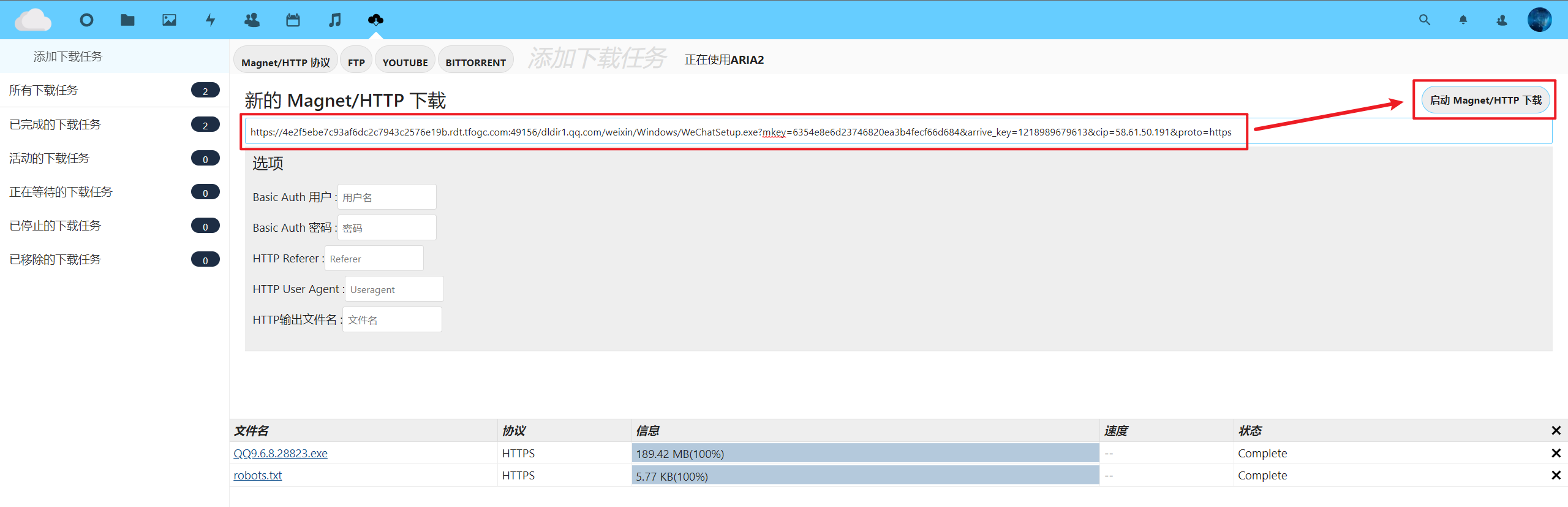
可以看到,下载是可以正常启动,并可以看到历史的下载记录的:

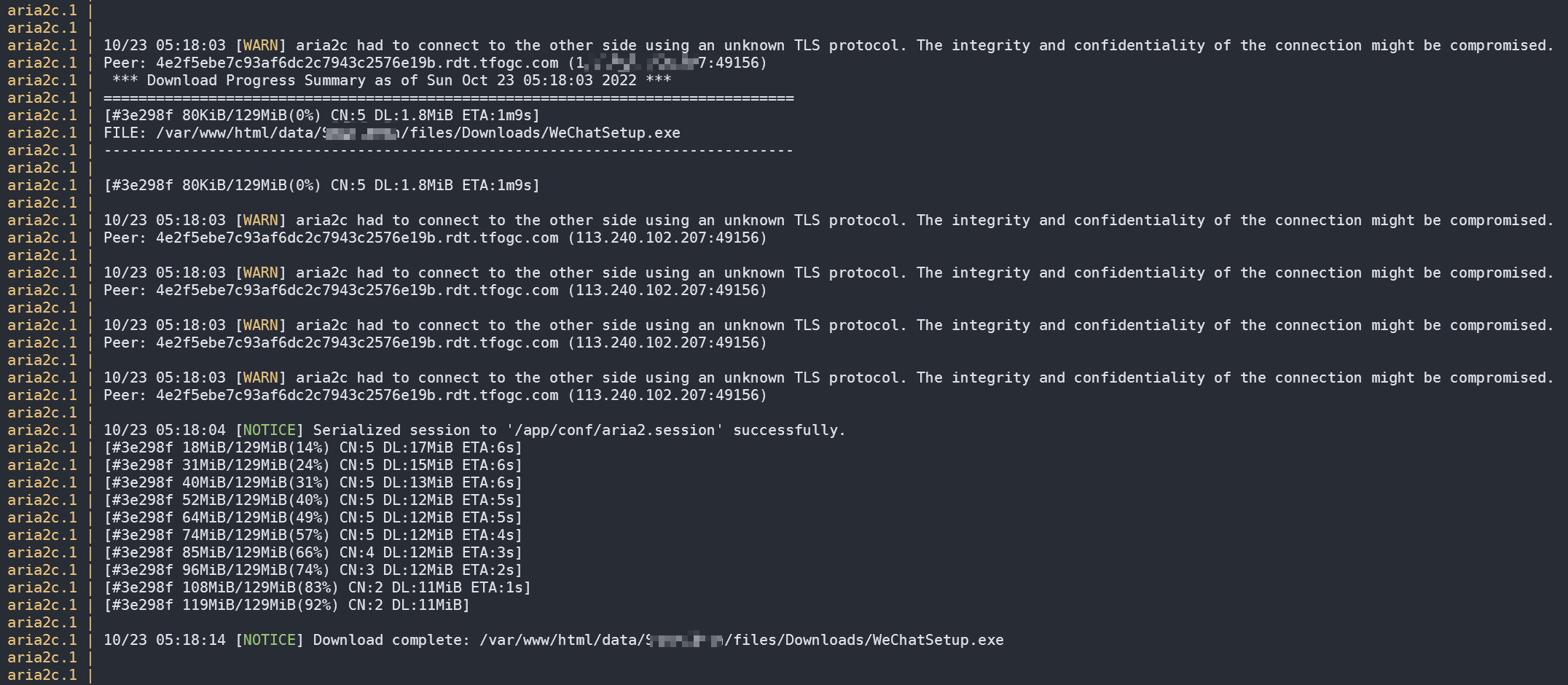
从 Aria2 容器的日志中也可以看到下载的创建、进行情况:
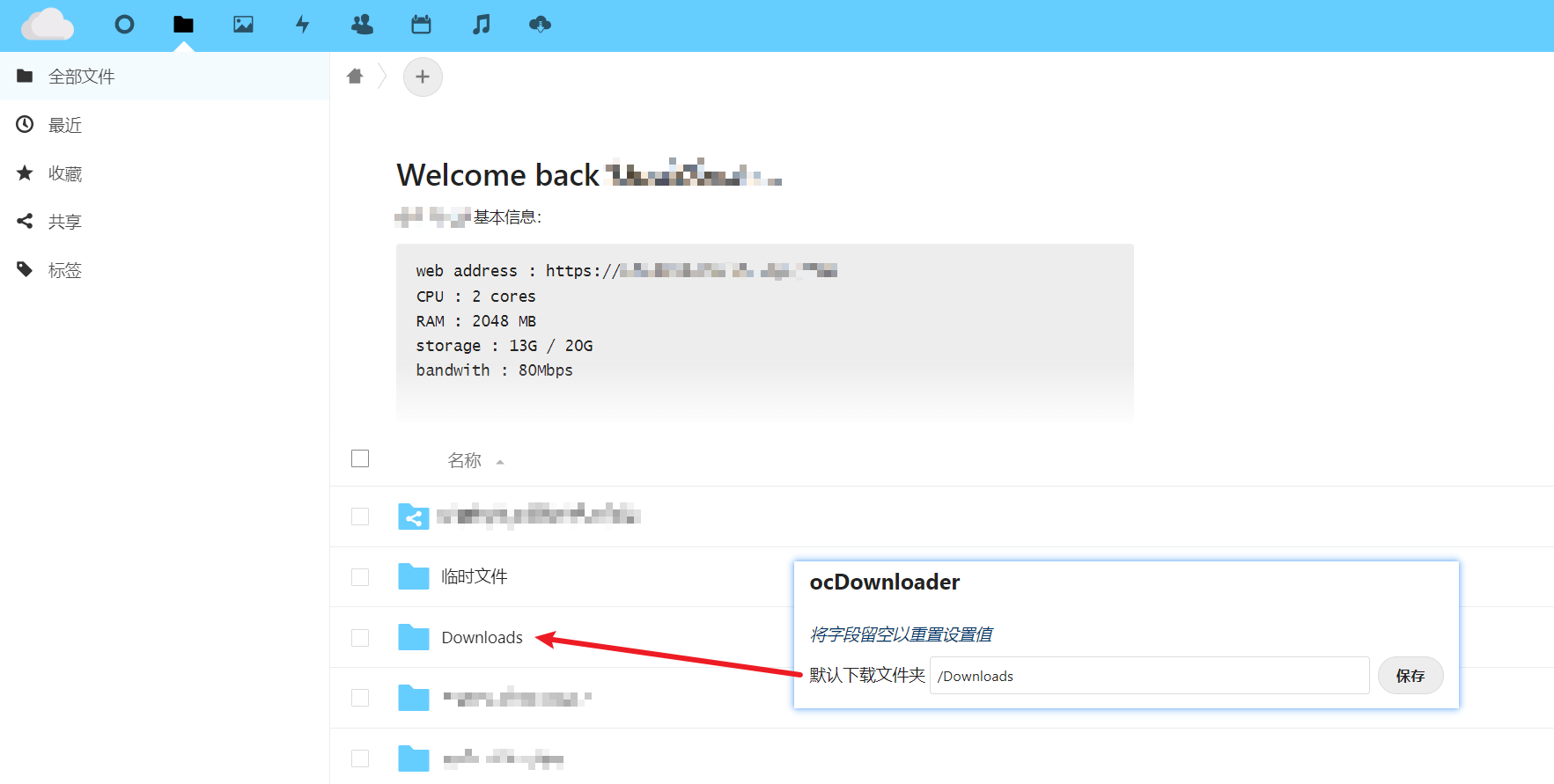
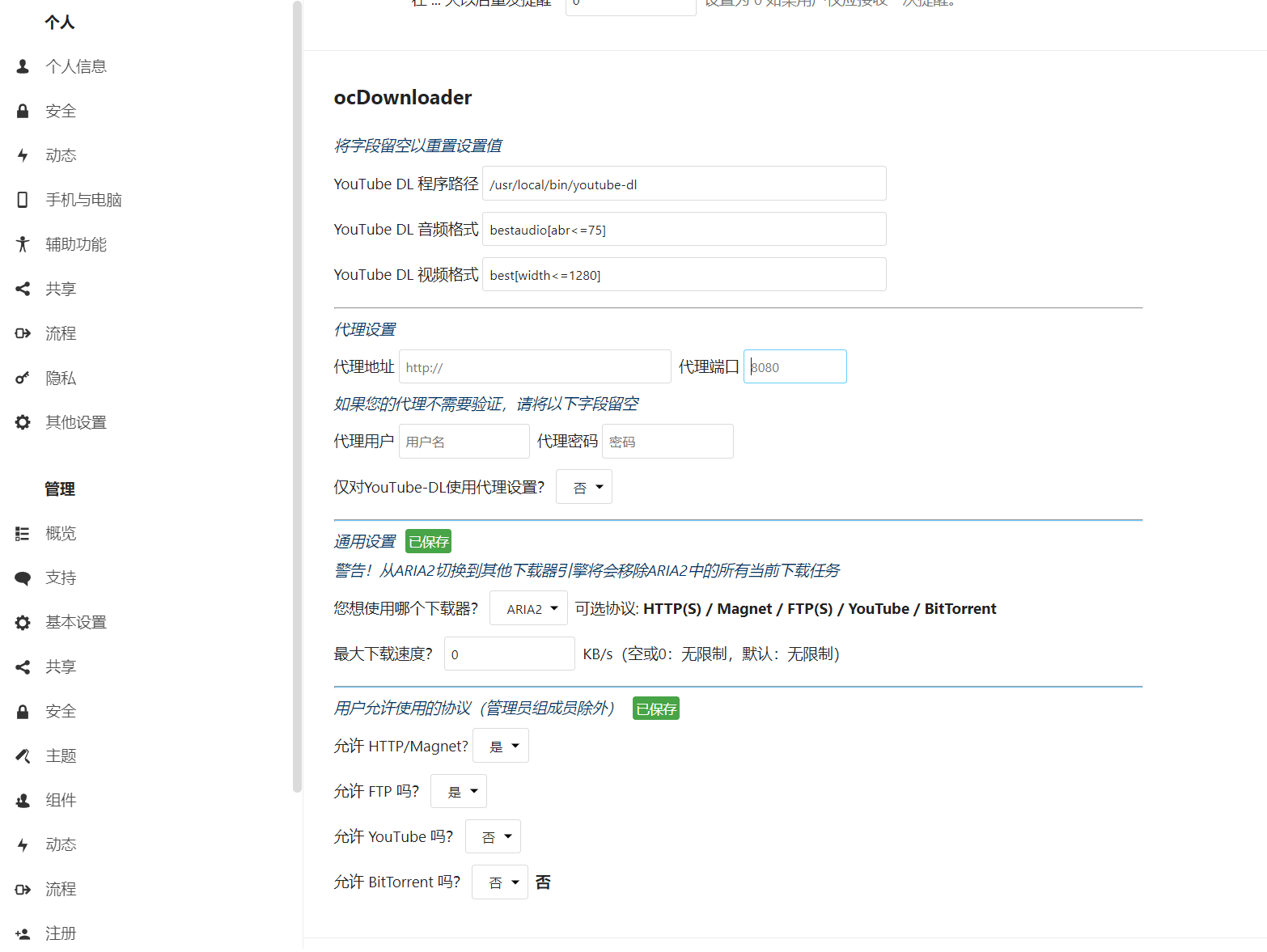
ocDownloader 配置项
打字太麻烦了,贴张图把
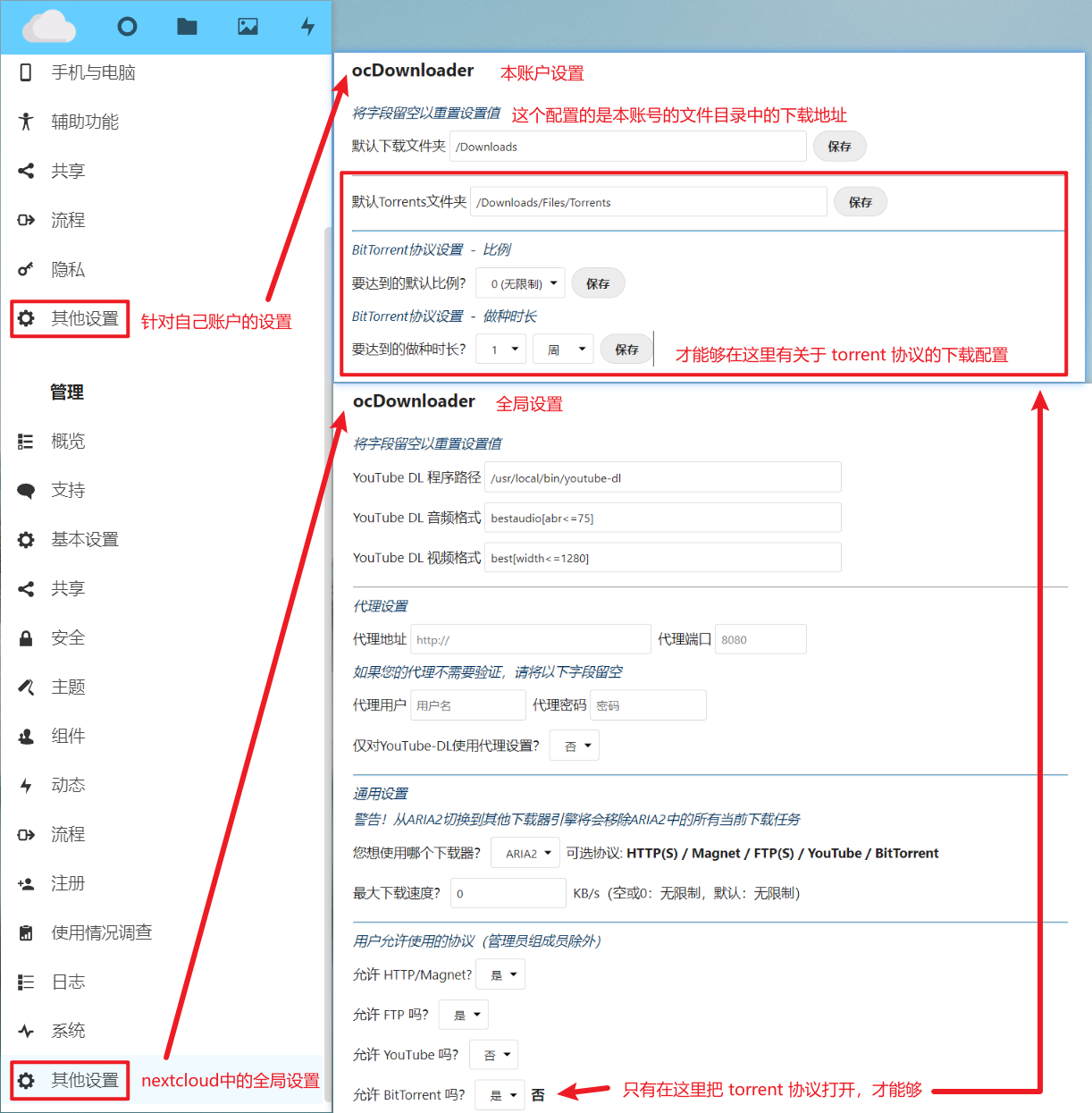
在默认下载文件夹参数中配置了目录后,就会在个人的文件页面中创建对应的目录,并下载到这里面。